Getting Started
Initial steps to deploy and configure the Automatic Models Training Engine
3 minute read
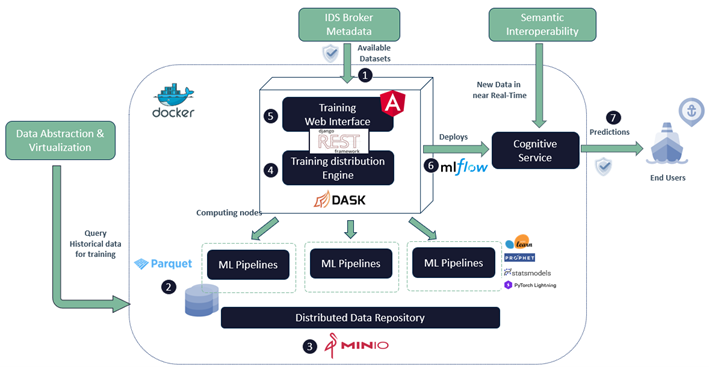
The Automatic Model Training Engine is a technical solution to create cognitive services for Ports’ stakeholders. From a set of datasets available in Dataports’ platform, this component provides a web training interface to automatically create an underlying Machine Learning model to predict a specific port KPI, such as the expected time of departure of a vessel or the tons of goods predicted for the following weeks. An end-user can define some relevant options of the training data pipeline process either to increase the accuracy of the predictions or to reduce the training process time. As an illustration, for the prediction of the ETD of a vessel, the end-user can include the information of the arrival terminal and the shipping operator. This process, usually named as feature engineering, is important for the training process, as domain experts are the ones who truly understand which data is potentially useful in a business scenario. Internally, the component implements a set of predefined training pipelines, using state-of-the-art ML algorithms for domains of regression, forecasting and classification, such as time series forecasting or automatic values imputation. By utilizing a distributed approach, several instances of such pipelines are executed simultaneously to better search, without the need of manual intervention, the most accurate model for the specified business goal. Finally, the resulting model is wrapped as a REST Service which can be deployed as a cognitive service.
The main input of the component is a collection of datasets available in the context of the DataPorts ecosystem. To achieve a distributed training approach, an approach to replicate the data in several hosts and avoid network latency due to data transfer was implemented. The distributed training approach was implemented using Dask, which is a framework that introduces parallelism mechanisms for Python scripts thus, enabling performance at scale for the most common ML frameworks. File size is a relevant metric, therefore Apache Parquet was selected to store datasets, because parquet file system offers a great data compression as the data type for each column is similar. The mentioned imported datasets are ultimately stored and replicated in a MINIO server. To enable the tracking and exploration of the trained models, MLFlow was implemented. MLFlow is an open-source platform to manage the machine learning lifecycle, including amongst others, experimentation, models tracking and deployment of machine learning models. To simplify the interaction of end-users with the component, a Training Web Interface was implemented, so it directly communicates with Django API to start the distributed training according to the end-user requirements. Regarding the component deployment, subcomponents have been packaged by using Docker, so it can be deployed in any infrastructure. Finally, once the cognitive service is constructed, an end-user can make use of it by connecting throughout a specific endpoint.
To have a quick overview of the component, see the video below which represents an example of how to use the Web User Interface to fully utilize AMTE.
Initial steps to deploy and configure the Automatic Models Training Engine
User guide to understand how the software is used
OpenAPI specification to interact programmatically
Links to the source Code available at eGitlab
(Optional) Additional documents worth reading