How to use
10 minute read
Overview
The Automatic Models Training Engine is a technical solution to create cognitive services for Ports’ business KPIs. From a set of already imported datasets, this service provides a to stakeholders a training dashboard to automatically create an underlying model to answer a specific port KPI. Data is not permanently stored in the component, but rather imported when needed, by using the discovery metadata mechanism provided by the DataPorts platform. Such data is then made available to the end-user so as to select a specific KPI. This process, usually named as feature engineering, is important in the further training process, as domain experts are the ones who truly understand which data is potentially useful in a business scenario. Internally, the component implements a set of predefined training pipelines, using state-of-the-art ML algorithms for domains of regression, forecasting and classification, such as time series forecasting and missing values imputation. Using a distributed approach, several instances of such pipelines are executed simultaneously in order to find, without the need of manual intervention, the most accurate model for the end-user defined goal. Then, the resulting model is wrapped as a REST Service which can be deployed as a cognitive service.
Cognitive Services
The component provides six cognitive services that the user can select and configure according to their needs. The offered services are showed below:

A more detailed explanation of each cognitive service is described as follows:
- Vessel Time of Departure Estimator. This service estimates the date and time of departure of an arriving vessel.
- Vessels Port Calls Calculator. Service that calculates the amount of port calls that will be expected to occur in a specific port/terminal for a determined time horizon selected by the user.
- Average Vessel Berth Time. This service calculates the averaged berth time of a potential vessel docked in a port/terminal for a determined temporal horizon.
- Customs Trade Volume. Estimation of the volume of a certain type of good (in tons) from/to a specific district in a certain time horizon, in months.
- Container Goods Volume. Estimation of the quantity of TEUS of a certain type of good from/to a specific district in a certain time horizon specified by the user.
- Missing Origin/Destination Identification. Prediction of an unknown district in the historical data of the dataset “port traceability (hinterland)” from ValenciaPort.
Training Strategies
Each of the training strategies defines a custom configuration of the standard pipeline by adding or avoiding some of the data processing steps. The selection of the most suitable training strategy is left up to the user and it will directly affects both the amount of precision of the model trained and consequently, the training time required to obtain the predictive model. The four available training strategies are showed in the following figure:
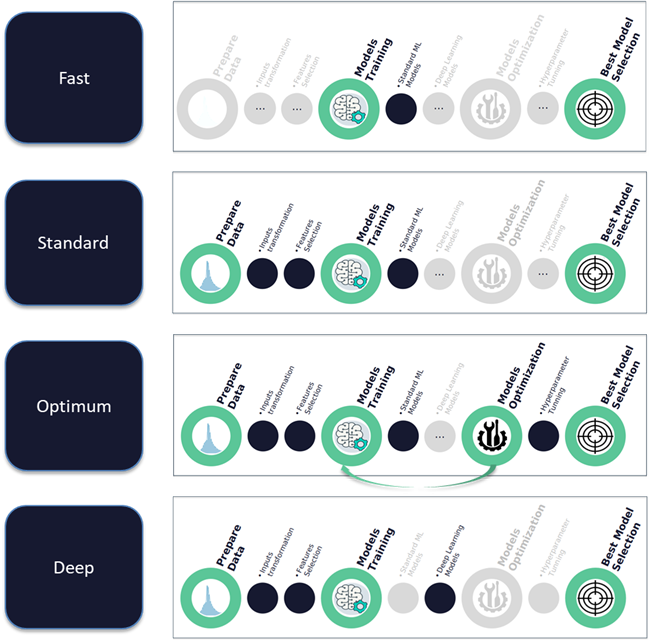
The four available training strategies are described as follows:
-
Fast Training Strategy: A quick training process will be carried out to obtain the forecasting outcome as fast as possible. Hence, some processing steps such as inputs transformations or features selection will be avoided. Additionally, the step of the search of the best hyperparameters combination, usually is the most time-consuming step due to its high computational cost. In the end a set of standard algorithms with default parameters will be trained and the model with the best quality metric will be selected to make future predictions.
-
Standard Training Strategy: First, a set of mathematical transformations will be applied to the inputs to enrich the dataset and find intrinsic patterns within the data. After that, a thorough feature selection process will be performed so the most important independent features will be selected. That will enhance the data quality for the training process. The set of algorithms remains the same than in the previous one, but better-quality metrics are expected with not so much overhead in the training time.
-
Optimum Training Strategy: This strategy adds optimisation steps into the pipeline to outcome the best possible training configuration. The main improvement resides in the hyperparameters optimisation step which performs a grid-search process where several combinations of parameters will be tried with each of the available algorithms. As each combination implies the training of a specific model, this strategy is recommended to be ran in a distributed environment with several nodes.
-
Deep Training Strategy: This training strategy is like the standard strategy, but it differs in the utilisation of Deep Learning algorithms. In this case only neural networks with more than one hidden layer will be trained. DL algorithms are usually able to find very complex patterns within the data, but they require high computational cost and a lot of time to converge. Additionally, they do not highly benefit of the optimisation of the previous approach. This strategy is expected to be the most time consuming.
Example of Use
To use the component, a frontend is available to the user on the following URL.
The main interface presents a list of the already existing cognitive services and their status, i.e., if they are currently running, stopped, deployed… Additionally, a selectable menu is provided on the left-hand side (see figure below):

- Services: Shows the main interface that lists the existing cognitive services
- Create: A wizard to specify a new service and kick off the training and search of the best ML model to make the predictions
- Models: Shows detailed information of the collection of ML models for each trained cognitive service
- Results: Presents the predictions made by a trained cognitive service as well as an interactive dashboard to analyse the results
Note: For a full example of Use demonstration see the section “5.3 Example of Use: Demonstration” of the deliverable [D3.3 Analytics]
Creation of a cognitive service
To create a new service, select the tab “Create” available on the selectable menu. In the first step, “Task”, the end-user defines a service name and its optional description as to what it is expected to accomplish. Then, the wizard provides several cognitive services to fulfil a specific type of prediction, such as forecast the ETD of a vessel or calculate the received tons of a specific good for the next months.

The second step of the wizard is named “Dataset”.
In this step (see figure below), the user is presented a searchable list of available datasets is presented on the DataPorts platform, which provides the data required to create the service. Only datasets with the required data are available for selection. For instance, if the user requires to predict the vessel ETD, only datasets with historical records of the arrival and departure of vessels are shown. This dataset filtering is achieved using the functionality of the Semantic Interoperability API and the DataPorts data model. It is important to highlight those datasets are only available if permissions are already granted to an organisation using the data governance functionality of the platform. To be compliant with the security and governance guidelines, they are deleted from the component infrastructure when the training process is finished.

The third step, called “Configuration” (see figure below), is specific for each service.
In this screen, the user can choose additional information or options to be considered for training the underlying models. For instance, in the configuration of the service Vessel Average Berth Time, the end-user could select consider only vessels arriving to a specific terminal or port, as terminals in the same port have different processes and traffic, mixing information from different ones could lead to low accuracy in the prediction. Additionally, the service could be configured to predict using a chosen time granularity: predict the average berth time for the next days, weeks or months. A proper configuration of such options could greatly impact the model’s accuracy. In the case of the configuration of Cognitive Services associated with a time variable, the option “Consider only last year of data for training” will be available. Hence, more accurate models may be trained as the training data is closer to the time of the prediction. It is worth to mention, that only options relevant to the end-user expertise are available, avoiding options related with the underlying ML training process.

The fourth step is named “Strategy” (see figure below).
This screen shows a list of the different training strategies, already introduced in the previous section. The end-user must select any of them depending on its time availability and performance requirements. Depending on the strategy selected as specific set of algorithms and associated parameters will be automatically choose by the training engine.

The final step is named “Confirmation” (see figure below).
In this step, the detailed information of all the choices and selections made during the wizard are presented for reviewing. Once confirmed, the button Train Service starts the distributed training process of a ML model that implements the required service.

Management of a cognitive service
A cognitive service may have 4 different status:

- Training: The underlying data pipeline is working to search the best predictive algorithm
- Running: The cognitive service is deployed and available to make new predictions
- Stopped: The cognitive service is undeployed and cannot make new predictions
- Ready: The best predictive algorithm was trained and the pipeline finished
Existing cognitive services can be subjected to a series of actions, so they can be managed:

- Deploy a service (1): The service can be deployed, so it is able to perform new predictions and its outcomes can be explored in the results section. The status will change to “Running”.
- Stop a service (2): The service can be stopped, therefore it will be unable to perform new predictions and it will be weed out from the results section. The status will change to “Stopped”
- Delete a service (3): The service can be deleted, hence it will be removed from the list of available services
- Analyze a service (4): Detailed technical information about the service can be analyzed by clicking the button named “More Info”. This option is visible through the dropdown button with three dots on the right side of the service. The new screen shows information related to the algorithms trained, the best model found selected, the training time and the current accuracy metrics.
Once the button “More Information” is clicked, the following screen appears:

Analysis of the results of a cognitive service
Once the cognitive services have been trained, their outcomes can be visualized on the option ‘Results’ of the left panel. The results section is divided into 3 types of cognitive services:
- (I) Port Services: Services related to the management of the ports/terminals
- (II) Product Services: Services related to the analysis of products
- (III) Missing Values Services: Services related to the imputation of missing values within a dataset
(I) Results of “Port Services”
The first result present the outcome of the service Vessel Time of Departure Estimator and it is showed in a tabular format. The data showed is a small extract of the real data extracted from the Port of Valencia in Real Time (to analyze the whole table of vessels, click the button “View Full table”), whereas the last column is calculated by the best predictive model trained in the cognitive service, and represents the expected time of departure of a vessel as illustrated in the next picture:

The graph on the bottom-left represents the estimated occupation of ports/terminales based on the selected trained service of type Vessels Port Calls Calculator.
The graph on the bottom-right shows the expected average berthing time based on the selected trained service of type Average Vessel Berth Time, as illustrated in the next picture:

(II)Results of “Product Services”
The graph on the top-left represents the expected values in Tons of the selected trained service of type Customs Trade Volume.
The graph on the top-right shows the forecasted values in TEUS of the selected trained service of type Container Goods Volume, as illustrated in the next picture:

The graph on the bottom-left represents the countries ranking based on the selected trained service of type Customs Trade Volume.
The graph on the bottom-right shows a ranking of all the products, based on the selected trained service of type Container Goods Volume, as displayed in the picture below:

(III) Results of “Missing Values Services”
The graph on the top-left represents the accuracy of the best predictive model trained for the service of type Missing Origin/Destination Identification. The graph on the bottom-left shows the amount of importance of each variable of the dataset to predict the missing values. The graph on the top-right, displays the percentage of missing values filled up for each of the possible categories.

Contributors
- Francisco Valverde - @fvalverde - Technical Project management
- Miguel Bravo - @mbravo - Data processing and analysis
- Pablo Ruiz Sánchez - @pruiz - Data processing and analysis
- Manuel Sánchez - @msanchez - Web and dashboard development
- Enrique Miravet - @emiravet - Frontend and backend development